
Apple Researchers Challenge the "Reasoning" Hype in Frontier AI Models
Apple researchers have challenged the prevailing narrative around AI "reasoning," showing that large language models often fail when faced with slightly altered math problems. Their study suggests these models rely on pattern matching from training data rather than true logical thinking. This raises concerns about how capabilities like reasoning are defined and marketed in the AI industry.
MODELS
The AI Maker
5/29/20252 min read

In an industry flooded with buzzwords and bold claims, "reasoning" has emerged as one of the most frequently flaunted capabilities of advanced AI systems. From corporate keynotes to promotional blog posts, AI companies frequently trumpet their models’ ability to think, infer, and solve problems with seemingly humanlike logic. But a new study from Apple researchers throws cold water on that narrative, suggesting that much of this so-called “reasoning” might be marketing smoke and mirrors.
The study, which is currently awaiting peer review, examines the logical chops of large language models (LLMs) like OpenAI’s much-hyped “Strawberry” model — now renamed “o1.” These frontier models are touted as capable of high-level reasoning, but Apple’s investigation finds that the actual mechanics of this reasoning are fragile at best.
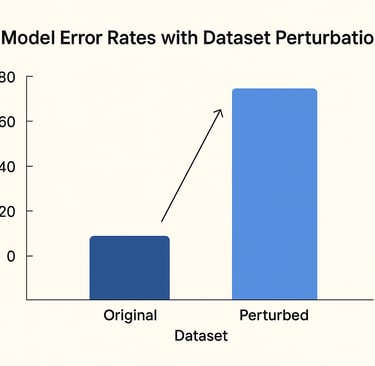
To test these claims, Apple’s team zeroed in on the GSM8K benchmark, a standard dataset made up of grade-school level math word problems. This benchmark is widely used in the AI research community to evaluate a model’s reasoning ability. But instead of taking the dataset at face value, Apple’s researchers decided to test how LLMs handle small perturbations — changes that shouldn’t affect the answer but might trip up a model relying on surface patterns.
The results were eye-opening. When researchers altered the problems in simple, seemingly inconsequential ways — changing a number, swapping out a character’s name, or introducing irrelevant narrative details — the models’ error rates jumped significantly. This strongly suggests that the models aren’t “reasoning” in any meaningful human sense. Instead, they appear to be leaning heavily on memorized patterns rather than flexible logical thinking.
This undermines a key assumption behind the hype. If LLMs struggle with minor changes that don’t affect the logic of a problem, their reasoning isn’t robust — it’s brittle. As the Apple researchers put it, “[LLMs] attempt to replicate the reasoning steps observed in their training data,” rather than engaging in genuine logic. In other words, the AI is mimicking reasoning, not performing it.
These findings raise broader questions for the AI industry, particularly around how capabilities are marketed to the public. Terms like “reasoning,” “intelligence,” and “consciousness” carry strong human connotations, but without shared definitions or reliable evaluation methods, they risk misleading users and investors alike. For companies like OpenAI, Anthropic, and others racing to showcase ever more “intelligent” systems, the pressure to overstate capabilities is real — and problematic.
It’s worth noting that Apple, traditionally secretive about its AI research, has begun to step more publicly into the field. This study may signal a broader willingness to challenge the industry’s assumptions and push for more rigorous standards in how we measure and communicate AI performance.
At the end of the day, the conversation around AI reasoning might not just be about better benchmarks — but about redefining what we expect these systems to actually do.
Cited: https://futurism.com/reasoning-ai-models-simple-trick
Your Data, Your Insights
Unlock the power of your data effortlessly. Update it continuously. Automatically.
Answers
Sign up NOW
info at aimaker.com
© 2024. All rights reserved. Terms and Conditions | Privacy Policy